Its been a long time
since my last blog article, having changed jobs late last year and being in
"the zone" getting up to speed with how my new company operates, and responding to new challenges that my new role brings. However I recently had a chance to utilise
Amazon Web Services' S3 service for publishing map tile caches, and since I
wasn't able to find a great depth of information on the subject I figured I
would post about it.
While I say I
couldn't find much information about publishing map tile caches in S3, I was
able to find a lot of blog posts talking about the subject, but found some of
these to be fairly general, or I struck issues that I could not find
information on resolving. In my case I
needed to publish an Esri map tile cache generated from ArcGIS Server, and
consumed by a HTML/Javascript application that utilised the ArcGIS Javascript
API.
I found a lot of
helpful information on the subject from the following blog pages, and I thank
the authors for their information -
- Mansour Raad
- Azavea Labs
- ROK Technologies Article and Presentation
- Esri Blog Article - published after I completed my project :)
As I mentioned I
found some of these articles to be a little generalised relating to the way
that the tiles were stored in S3, and in some cases how they were being
consumed. The steps below detail how I
was able to publish my map tiles.
Cache Generation
Since the end result
we are seeking to achieve is to access map tiles from S3, rather than
requesting tiles from ArcGIS Server, the map tiles will need to be created as
an Exploded cache, rather than a Compact cache.

The reason for this
is that an Exploded cache will create the tiles as separate image files, in my
case PNG files. A Compact cache stores
tiles in groups inside a single file called a bundle file, from which ArcGIS Server
will retrieve the requested tile. Web
applications/browsers cannot consume a bundle file directly because it is a
format utilised internally by ArcGIS Server.
Cache Directory Structure
When the cache
generation process executes the tiles will be produced in directories
under -
C:\arcgisserver\arcgiscache\<SERVICE_NAME>\Layers\_alllayers
Within this
directory there will be a subdirectories which represent each scale Level of
the map tile cache. Each level is
prefixed with L, and is represented as a level integer starting from the
highest zoom scale, moving down to the most detailed zoom scale having the
largest level integer.
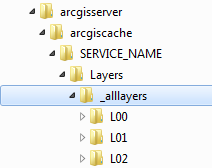
Within each Row
directory will be the map tile files themselves, represented as Columns.

Within each Row
directory will be the map tile files themselves, represented as Columns.

Something to note is
that the Row and Column integer values are represented in hexadecimal, with the
directory/file name prefixed by R and C respectively.
S3 Structure
There is a lot of
literature that describes what S3 is, especially on the AWS website, but as a
quick backgrounder (related to the way the map tiles will be stored), S3 is
basically a storage container for objects which can be accessed by a key. This differs from a typical disk storage
structure that breaks a volume up in to hierarchies of directories, and stores
files in those directories, referencing them by their path within the directory
structure.
Within S3, a
"bucket" can be created, which represent a storage area for a
collection of key/object pairs. The Esri
blog article mentioned above goes into more detail about S3 and configuring
buckets etc, so I will not reproduce that information.
The interesting
thing about the key/object storage of S3 relating to the cache structure
described above, is that the objects stored in S3 can be keyed in such a way
that their keys represent a relative path from the bucket name, thereby
mimicking a typical disk storage structure.
It is via this capability that I maintained my map tile cache in the
same relative structure to the way it was generated by ArcGIS Server.
To copy the cache I
used a utility called Cloudberry S3 Explorer.
This allowed me to copy a file structure on disk to my S3 bucket. In my case I copied the _alllayers directory
over into the S3 bucket.
Note that a map
cache can, and most likely will contain hundreds of thousands, or even millions
of individual map tiles, and since S3 is effectively a REST service that
provides GET, PUT, POST, DELETE actions on the bucket, to PUT each individual
file in the S3 bucket on the Amazon Cloud from a local machine will take a long
time to process, especially if the region the bucket resides in has a
relatively high network latency back to the local machine.
A better approach
would be to either generate the map tile cache on an EC2 instance running in
the Amazon Cloud in the same region as the S3 bucket, or, if the cache needs to
be copied from a local machine, zip the cache into a single zip file, or a number
of zip files depending on the overall size of the cache, and copy the zip files
to an EC2 instance, and then move them into S3 from the EC2 instance.
Consuming the Map Tile Cache
Now that the cache
has been moved to S3, we now want to consume the cache in our application logic
such that the map tiles are downloaded directly from S3 to the browser as we
pan around the map.
To do this our
application logic needs to know the specific details of the origin, scale
levels, pixel resolution of each scale level, etc of the cache. There are a couple of ways that this can be
achieved -
- Define the layer details in the application logic
- Fake the MapServer REST services directory json response
In both these
approaches, the application logic is only able to consume the pure map tiles
published in S3. Other functionality
related to the service such as accessing the legend, through the typical REST
endpoint will not be available.
Defining layer details in application logic
One way to define
the map service details for the TiledMapServiceLayer class is to define the
details within the class definition. The
ArcGIS Javascript API is based on Dojo, which provides functionality to define
javascript classes in a "classical" way similar to typical
object-oriented languages. This is done
by using the dojo.declare function to define the name of the new derived class,
the base classes that are being inherited, and the definition of the methods of
the new class.
Like languages that
use class based inheritance, the type defined in the declare function can have
a constructor which can initialise properties of the instance of the
class. In the example below you can see
the constructor method initialises the map service details such as
initialExtent, fullExtent, spatialReference, and most importantly for the tile
cache, the tileInfo, defining the levels of detail, their scales, resolution,
etc.
The only other
method is the overridden getTileUrl method which gets the tile image url based
on the level, row, and column number passed into the method. This is covered in more detail in a section
below.
Faking the MapServer REST services directory json
response
An interesting way
of supplying the tiled map service's details to the application logic is to
store those details in the S3 bucket along with the tiles themselves.
A number of the blog
articles referenced above discuss this approach, where they acquire the map
service's json document using the following URL - http://<SERVER_NAME>/arcgis/rest/services/<MAP_SERVICE_NAME>/MapServer?f=json
The response from
this request is then saved in a file called MapServer,
with no extension, and then saved to S3.
When accessed via REST, this has the effect of looking like a request to
the ArcGIS Server endpoint. The
Javascript API will apply a ?f=json query string parameter to the URL, but S3
will ignore it an pass back the file as a response.
By default files
stored in S3 will have a Content-Type header of application/octet-stream, so
the content header should be changed to application/json so that the client
receives the response with the header it expects. To change the Content-Type header I used
CloudBerry S3 Explorer, as shown in the images below -


The approach of
exposing the raw json in a file in S3 works ok if the website itself is hosted
in S3 as well, but if your website is in a different domain, then the ArcGIS
Javascript API will make cross-domain ajax request using JSONP. JSONP is an approach used to make requests to
services that don’t originate from the same site the page is published from by
padding (the "p") the JSON response with a callback function name,
and then injecting the entire response inside a script tag on the page. This means that for scenarios such as this,
the raw json is not enough to store in the MapServer file, otherwise the client
API will raise an error such as "Unexpected token :".
The source URL of the response that threw the error will give you a clue
as to how to fix the problem -
This indicates that
the response should look like a javascript function call to
dojo.io.script.jsonp_dojoIoScript1._jsonpCallback, passing in the raw json as
an argument, i.e.
dojo.io.script.jsonp_dojoIoScript1._jsonpCallback(<RAW_JSON_FROM_MAPSERVER_REQUEST>)
Part of the problem
of defining the MapServer file like this is that the function name will be
dynamic depending on when the ajax call is made from the client. In this case Dojo is calling the script
object dojoIoScript1 because it is the first ajax call that is being made. In theory there may be many of these which
are unable to be determined until runtime, so hard-coding the function name in
the MapServer file may not help.
In my opinion this
is more of a hack than anything else, but it was interesting to do from the
view point of seeing how it all hangs together.
In the case of my project, there was an intention to access the legend for
the service through the ArcGIS Server REST endpoint, so I came up with a hybrid
structure for the application logic which uses both ArcGIS Server for the
definition of the service and the other related endpoints, but uses S3 for
accessing the cache tiles. The hybrid
application logic is discussed further below.
If you don't want to
access the ArcGIS Server endpoint at all, then I would recommend the most
robust approach to be defining your own service details within the application
logic, as discussed above. If you want
to abstract your service details from the logic to get the tiles from S3,
simply use a configuration structure which passes the tiled service details in
the constructor of the class i.e.
Getting tiles from S3
Apart from the
application logic being aware of the cache's specifications, it also needs to
override the typical operation to get tiles from the cache so that it acquires
the tiles from the S3 instead.
To do this we
override the getTileUrl method, which is passed the level, row and column
details, and expects a URL to a tile in
return. The method is passed the level,
row and column numbers as integers, but as I mentioned earlier, the cache
created directories and files with hexadecimal values, so these integers need
to be converted to hexadecimal and have an L, R or C added to the level, row,
and column value respectively.
This path is
appended to the root of the cache location residing in the S3 bucket, and the
extension of the image file is appended to the file name.
The code examples
above illustrate this logic.
Hybrid Application Logic
The project I was
involved in needed to also access the legend for the tiled map service via a
legend widget, but due to the relocation of the cache to S3, this functionality
was not available. To get around this, our
ArcGIS Server instance was configured to retain the REST endpoint for the
cached service, but remove the physical cache tile images from the disk, and
moved these to S3.
In my application
logic I then created a "hybrid" tiled map service layer class (shown
below) which is supplied the ArcGIS Server service url, as well as the url to
the root of the cached tiles in the S3 bucket.
This results in the layer determining its definition from ArcGIS Server,
but then accessing S3 to get the cached tiles.
Conclusion
As you can see S3 is
a useful tool for storage of objects being accessed via REST, and map tiles are
a perfect candidate for this approach.
The storage of cache files on S3 appears to be more cost effective,
considering the level of availability of the S3 bucket, when compared with
achieving the equivalent with Elastic Block Storage (EBS), which is the Amazon
equivalent of virtual disk storage.
Another advantage of
S3 is that it can be paired with CloudFront, which is Amazon's content delivery
network service for delivering cached content to edge locations throughout the world,
which is useful for services which are utilised world wide.
Hopefully the
instructions above will help anyone who intends to expose map tiles in this
manner.
Thanks for sharing these use full information its was very help full to all owners.
ReplyDeleteDid you consider using S3 as a network drive with Cloudberry Drive?
ReplyDeletehttp://www.cloudberrylab.com/virtual-drive-amazon-s3-azure.aspx
Great technical article! Recently we worked on turning Amazon S3 into OGC WMTS service.
ReplyDeleteSee this video tutorial: http://youtu.be/A5gFXvxWIHM
or blog post http://blog.klokantech.com/2014/10/amazon-s3-as-wmts-cloud-hosting-for-maps.html
Maps published this way on S3 can be directly opened in any of the ArcGIS software as well as JavaScript viewers and open-source desktop GIS.